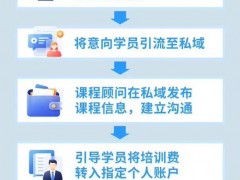
今年二月,OpenAI推出了首个文本到视频的生成模型Sora,其创新的一镜到底技术和高度统一的人物场景处理震撼了业界,将视频生成推向了年度技术热点之一。紧随其后,国内AI视频领域也迎来了前所未有的发展浪潮。

在最近的世界人工智能大会上,AI视频生成成为了焦点议题。众多创作者纷纷利用这一技术进行创意实验,如让甄嬛在视频中做出荒诞不经的行为,或让刘华强与瓜贩戏剧性地和解,甚至重现网络梗图中的夸张情景,这一切都得益于各种AI视频生成模型。
六月份见证了快手的可灵、Luma AI及Runway的Gen-3 Alpha等多个AI视频生成模型的集中发布,尤其是快手的可灵,被誉为中国的Sora,其生成视频的时长达到了120秒,并开放了多项功能,如图生视频、视频续写等。该模型在内测中展现出了惊人的能力,如模拟物理动态,赢得了极高评价,被认为是人工智能领域的又一重要进展。
尽管如此,当前的视频生成技术仍面临挑战,如可控性不足,难以保证人物形象、场景风格的连贯一致,以及运动流畅性、光影、语音自然度等方面的待优化。上海交大教授倪冰冰指出,生成算法常遇到结构和细节问题,比如物体的不正常增减、视觉错误等。她认为,尽管AI视频技术提升了生产效率,但在成熟的影视制作面前仍有差距。